Сборщики данных
Сборщики данных (Data Miners) - это инструмент для активного сбора данных (метод pull) с любых устройств и информационных систем (ICMP-проверки, SQL, HTTP проверки и запросы).
Сборщик работает как самостоятельный компонент системы и отвечает исключительно за получение информации.
Непосредственно получение информации происходит через агенты Monq или через сервис безагентского мониторинга.
Технология pull (англ. pull technology, pull coding или client pull - сбор чего-либо ) - технология сетевой коммуникации, при которой первоначальный запрос данных производится клиентом, а ответ порождается сервером.
Экран управления сборщиками данных
Экран управления сборщиками предоставляет централизованный интерфейс для настройки существующих сборщиков, создания новых конфигураций сборщиков, а также для контроля их работы.
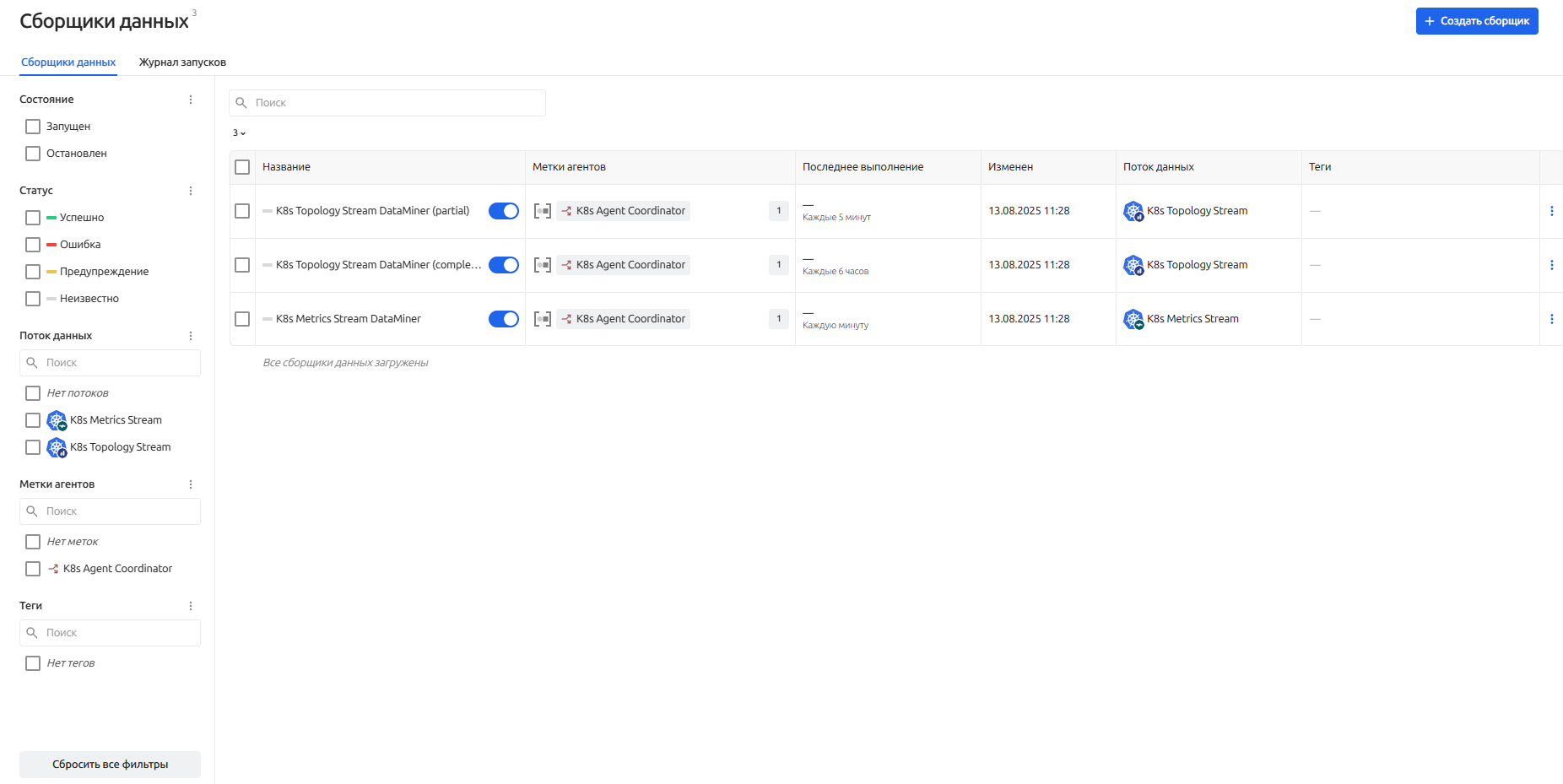
На вкладке "Сборщики данных" доступен рубрикатор для фильтрации сборщиков и непосредственно таблица с созданными сборщиками в системе.
При помощи рубрикатора пользователи могут фильтровать сборщики по следующим свойствам:
- Состояние - поможет показать только включенные или только отключенные сборщики
- Статус - отфильтрует сборщики по статусу выполнения заданий
- Поток данных - покажет только те сборщики, которые связаны с выбранным потоком данных
- Метки агентов - покажет сборщики, которые используют те или иные метки агентов
- Теги - фильтрация по назначенным тегам
Таблица со сборщиками данных отображает основную информацию о созданных сборщиках в контексте рабочей группы:
- Название сборщика данных
- Метки агентов, которые использует сборщик данных
Может отображаться запись "Система", что означает использование сервиса безагентского мониторинга
- Время последнего выполнения отображает статус, время и периодичность запуска сборщика
- Время внесения изменений в сборщик данных
- Связанный поток данных
- Теги
Доступ к экрану
Для работы с экраном сборщиков пользователю необходимы права:
- Просмотр – возможность видеть список сборщиков и журнал выполнения
- Редактирование – создание/изменение конфигураций сборщиков
При отсутствии прав, пользователи с Запретом получат ошибку доступа - 403 Forbidden.
Массовые действия
Работая с экраном сборщиков данных доступно выполнение массовых действий по удалению, запуску и изменении потока данных.
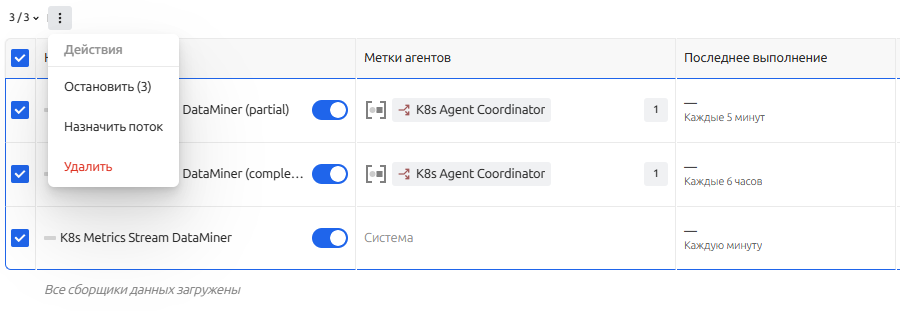
Массовые действия доступны через "кебаб"-меню при выборе одного и более сборщика данных.
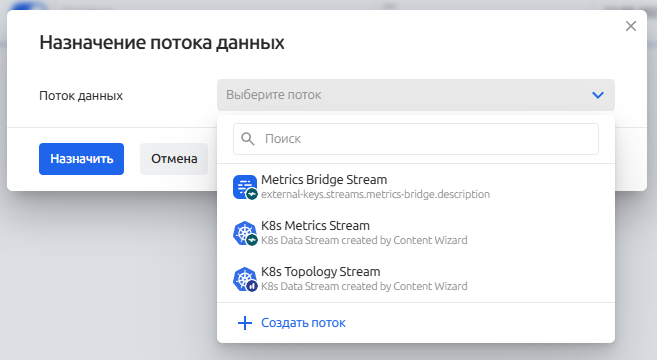
Пример назначения потока данных для всех выбранных сборщиков выглядит следующим образом:
Журнал запусков
Журнал запусков предоставляет детальную информацию о выполнении заданий сборщиками, помогая контролировать работоспособность процесса получения данных, оперативно выявлять и диагностировать сбои в работе.
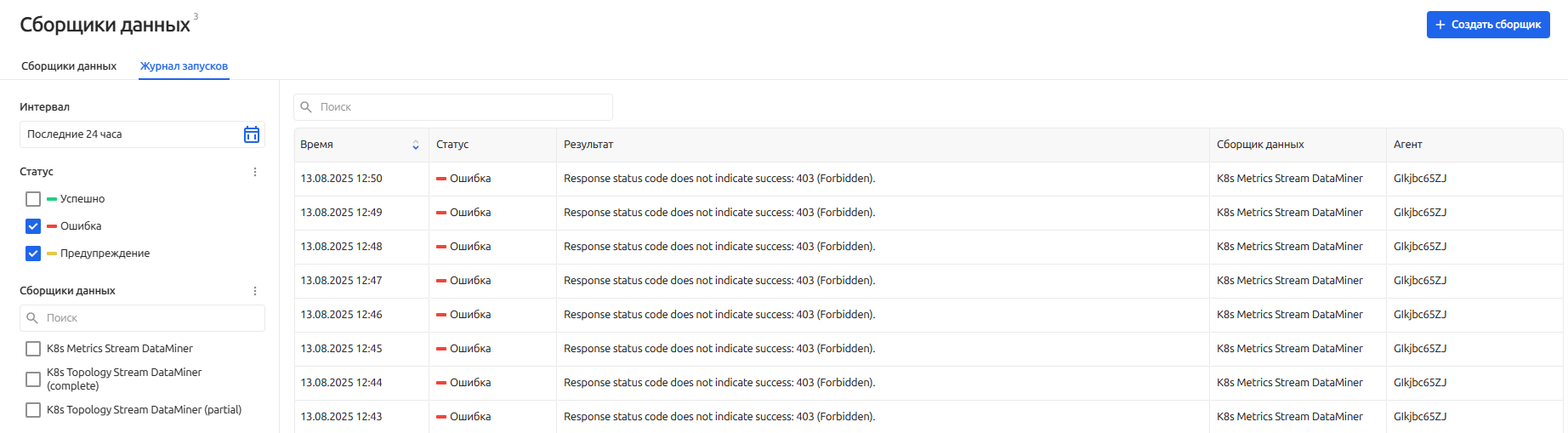
На вкладке Журнал запусков доступен рубрикатор для фильтрации результатов по следующим свойствам:
- Интервал времени в котором нужно посмотреть записи журнала
- Статус выполнения конкретного экземпляра задания
- Сборщик данных, который анализируется
В самом журнале отображаются записи:
- Время выполнения скрипта сборщика
- Статус с которым завершилось выполнение
- Информация с результатом выполнения
- Сборщик данных, который выполнял скрипт
- Агент, на котором выполнялось задание сборщика
При использовании сервиса безагентского мониторинга в поле Агент будет отображаться динамическое название системного агента.
Для получения уведомлений о проблемах со сборщиками данных расширен состав стартовых событий бизнес-процессов, блоком - "Статус сборщика данных".
Ручное создание сборщиков данных
Для создания нового сборщика данных выполните следующие действия:
-
Перейдите в раздел Сбор (ETL) - Сборщики данных через основное меню
-
Нажмите кнопку Создать сборщик в верхнем правом углу
-
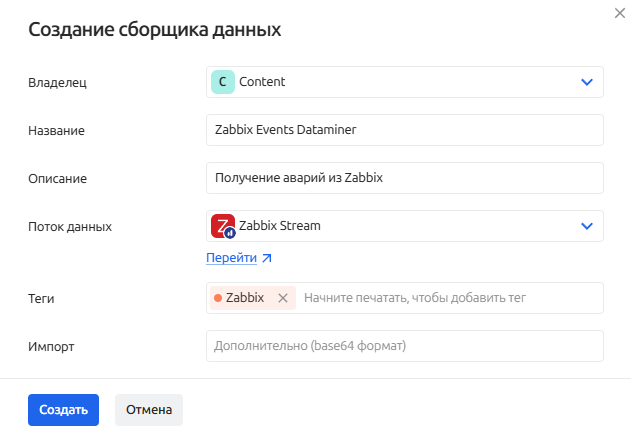
Заполните поля:
- Владелец - Рабочая группа, которой принадлежит сборщик данных
- Название (уникально в рамках Рабочей группы)
- Описание - опционально
- Поток данных - выберите доступный или создайте новый поток данных для хранения результатов сбора
- Теги - назначьте необходимые теги для удобства фильтрации и навигации по сборщикам
- Импорт - данные в формате
base64, которые содержат инструкции для создания сборщика данных с предустановленными настройками (например, экспортированные из другой системы)
-
Нажмите кнопку Создать - откроется страница настройки, добавленного потока данных
-
Дальнейшая настройка потока данных зависит от его типа и требований источника данных.
Создание сборщиков данных из мастера настройки
Пользователь может создать заранее подготовленные сборщики данных из контент-паков системы (например, Zabbix, vCenter и другие). Каждый отдельный контент-пак в Мастере настройки это набор предустановленных сущностей Monq (сборщики данных, потоки данных, сценарии и т.д.).
В имеющихся в мастере настройки контент-паках уже имеются предустановленные сборщики данных, объединенные с потоками данных.
Подробнее об установке сущностей из контент-паков можно узнать в разделе документации Мастер настройки, а также на примере Потоков данных, которые создаются в комплексе со сборщиками.
Настройка сборщика
Сборщик данных состоит из следующих блоков настроек:
-
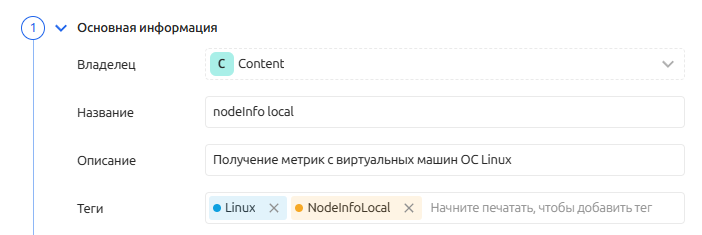
Основная информация - содержит информацию о владельце, названии и описании сборщика данных, а также о назначенных тегах. Задается при создании сборщика, по желанию можно отредактировать.
-
Параметры - блок предустановленных параметров, в том числе и защищенных, которые могут использоваться в скрипте сборщика
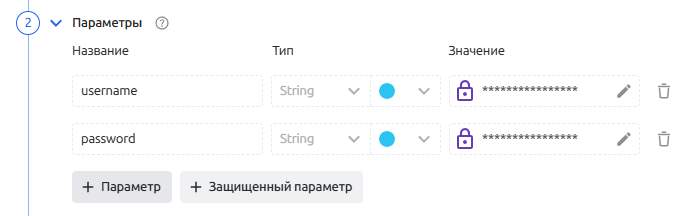
Чтобы воспользоваться значением параметра в скрипте необходимо воспользоваться шаблонизатором JSONPath:
$.var.[название-параметра]; или Liquid:{{ vars.[название-параметра] }}. Вместо шаблонизатора будет подставлено соответствующее значение параметра. -
Скрипт - представляет собой YAML-сценарий, описывающий логику работы сборщика
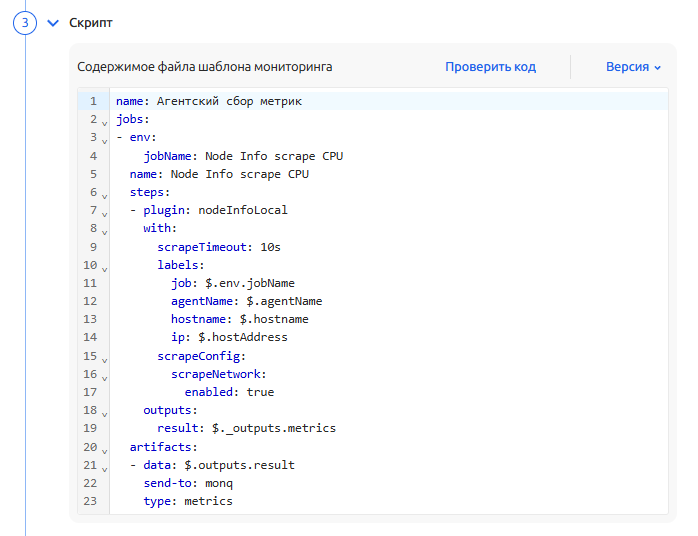
Подробнее про написание скриптов в разделе Синтаксис скриптов сборщиков. Примеры скриптов приведены как в данном разделе, так и в разделе с описанием доступных плагинов для monq-agent.
Встроенный редактор скриптов поддерживает версионирование. При внесении изменений в скрипт и сохранении - создается новая версия и всегда можно вернуться к одной из предыдущих версий вашего скрипта. Также в редакторе присутствует встроенный валидатор формата YAML.
-
Конфигурация выполнения - содержит параметры запуска и выполнения сборщика
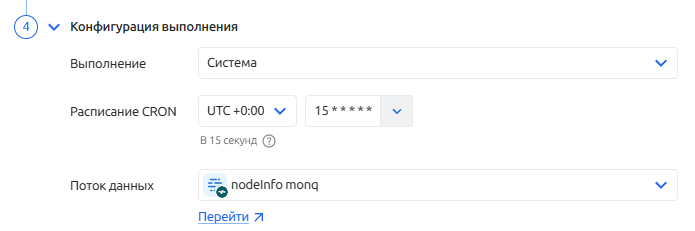
Конфигурация выполнения подразумевает то, как и где будет запущен скрипт сборщика.
Для опции "Выполнение" доступны следующие варианты запуска:
-
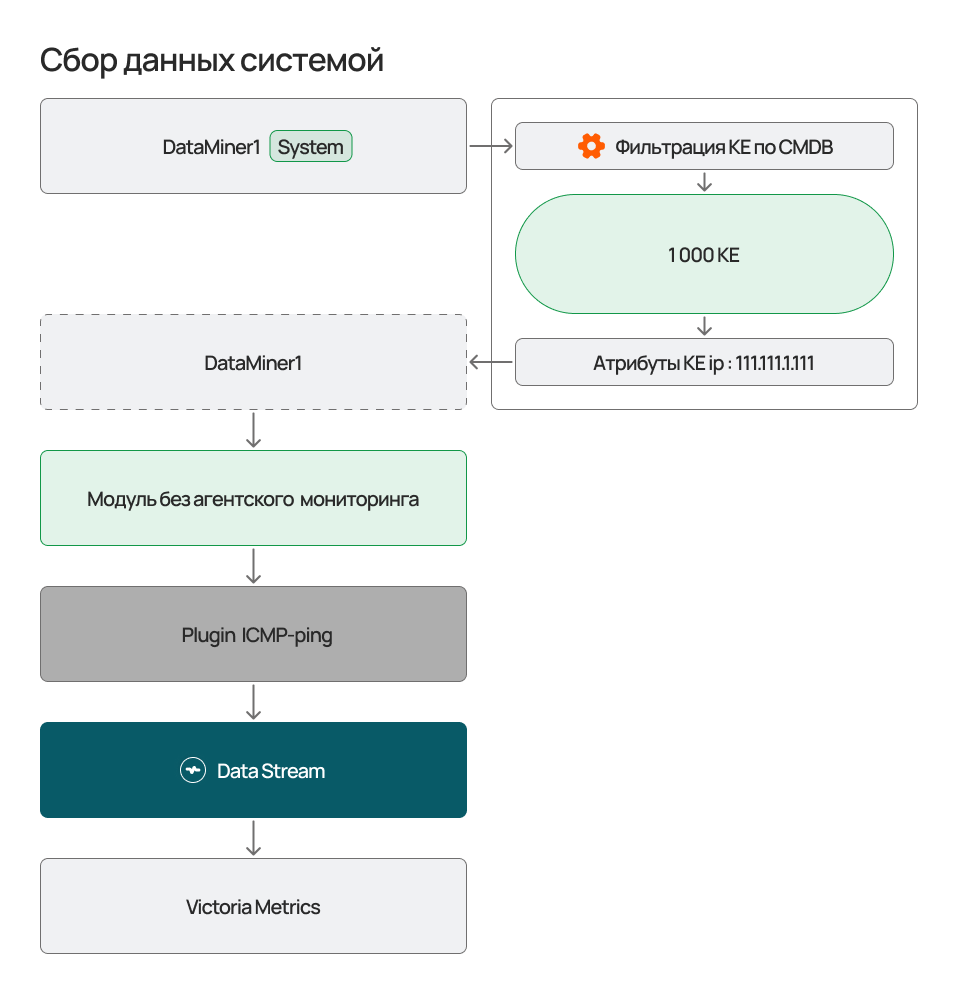
"Система" - скрипт будет запущен в сервисе безагентского мониторинга без привлечения агентов Monq. Используется при выполнении ICMP, HTTP, SNMP проверок с самой системы.
-
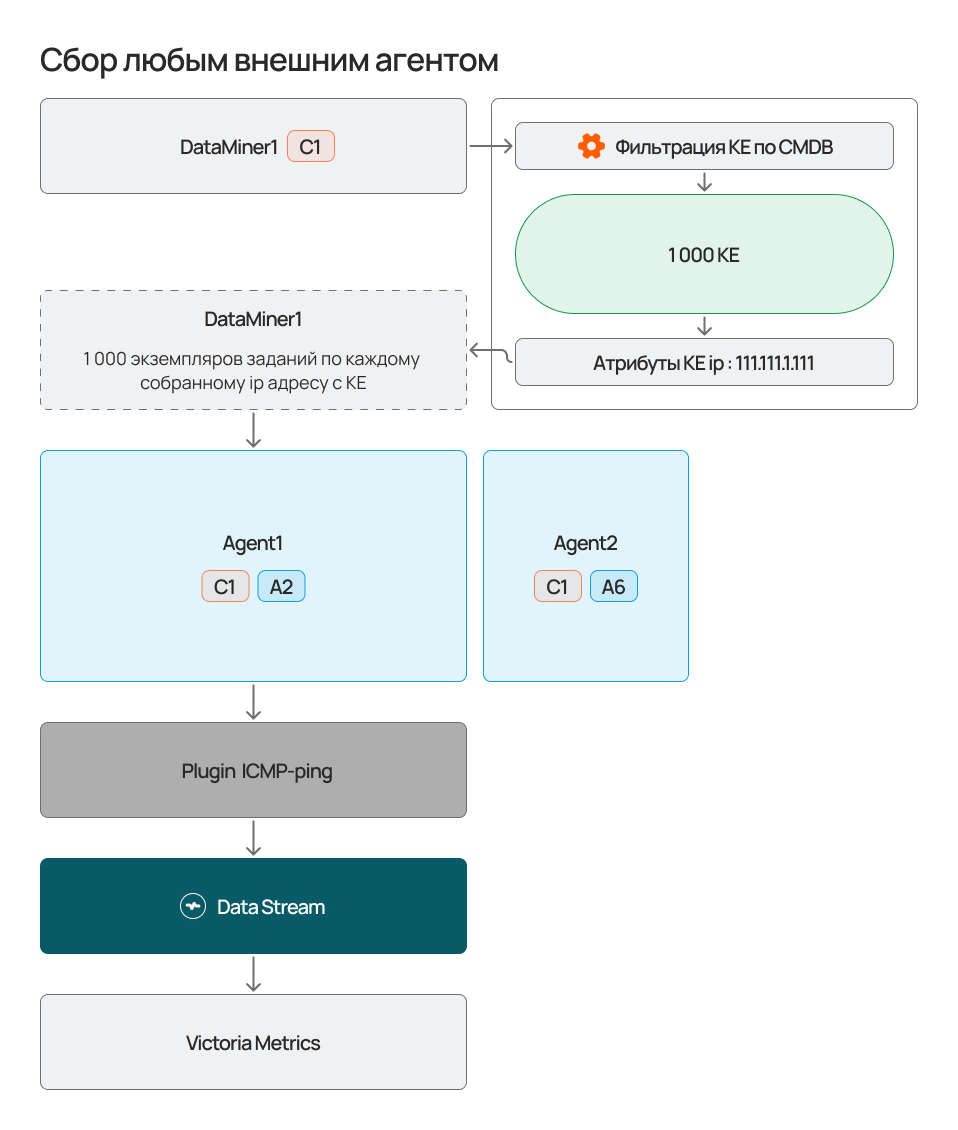
"На любом агенте" - скрипт будет выполнен на любом подключенном агенте с совпадающим набором меток. В данном режиме выполнения, агент используется как некий "прокси" в закрытый контур. Если все агенты заняты (нет доступных слотов) - задание будет поставлено в очередь.
-
"На всех агентах" - скрипт будет выполнен на всех агентах с совпадающим набором меток.
Является примером классического агентского мониторинга, например с плагинами NodeInfoLocal или WinInfoLocal, когда требуется получить данные с каждого узла, где установлен агент.
Если на момент запуска агента он будет занят (нет доступных слотов) - будет сгенерирована ошибка сборщика данных.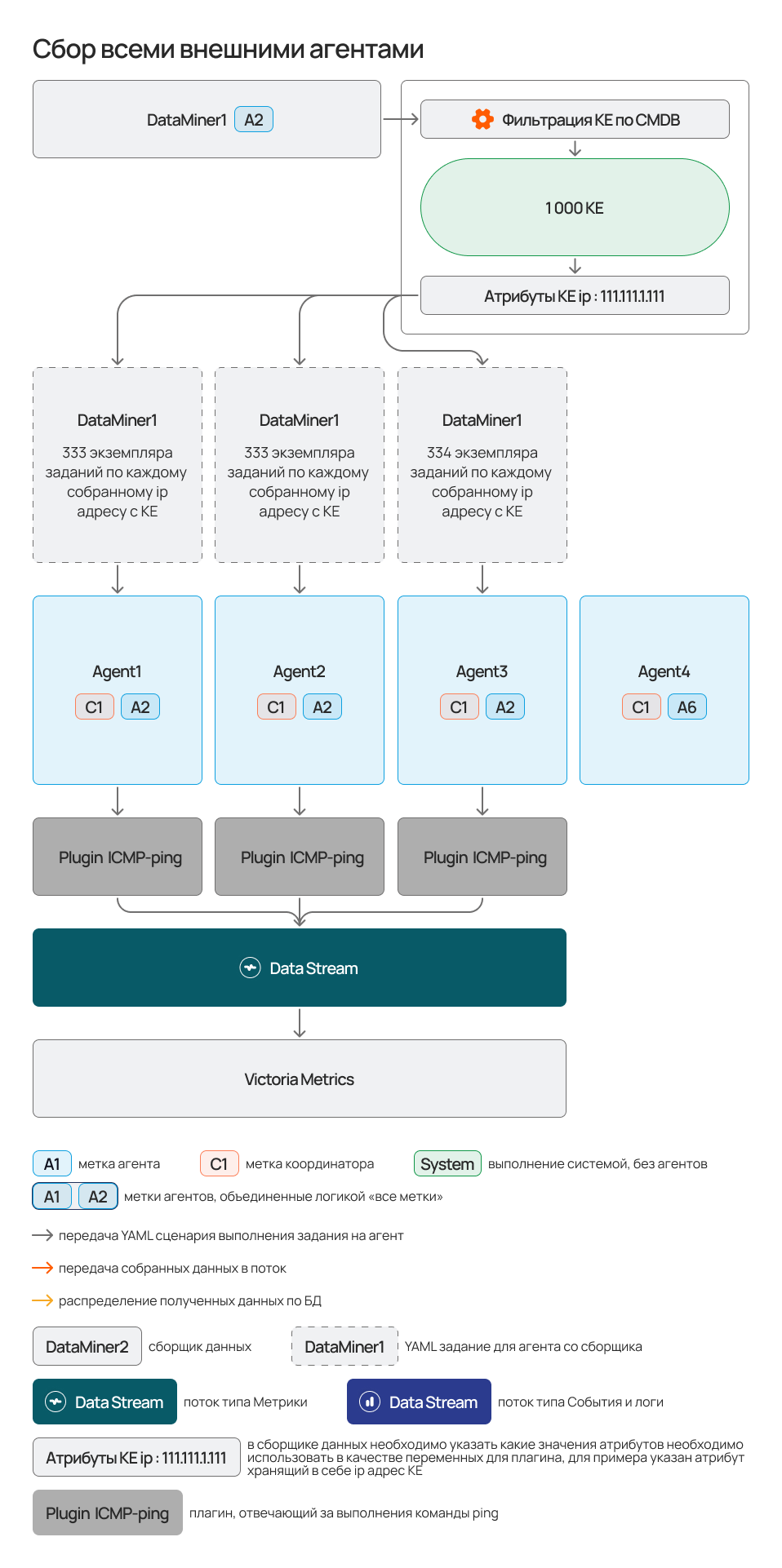
⚠️ В случаях, если время выполнения скрипта сборщика занимает больше времени, чем установлен интервал запуска, оно будет прервано следующим экземпляром выполнения. В статусе сборщика будет наблюдаться ошибка:
Agent task was cancelled by server as it was not executed before the next launch.Опция выбора "Метки агента":
- "Агент содержит любую метку из списка" - задание будет выполнено на агенте, содержащем одну из меток, перечисленных в списке
- "Агент содержит все метки из списка" - задание будет выполнено на агенте, содержащем все метки, перечисленные в списке
⚠️ Если указана несуществующая метка, (например, была удалена с агента, а в параметрах конфигурации осталась или пользователь сам указал несуществующую метку зная, что в будущем подключит такой агент) - пользователю отображается предупреждение, что конфигурация содержит метки агентов, которые не подключены или отсутствуют.
Предупреждение остается даже после сохранения.Расписание CRON - периодичность запуска задания в фоновом режиме (используется формат CRON)
Поток данных - результат (артефакт) выполнения сборщика данных будет отправлен в выбранный поток данных.
-
Сбор данных по CMDB
В расширенной версии лицензии Monq доступен сервис взаимодействия сборщиков данных с внутренней CMDB Monq.
Данный сервис позволяет получать различные данные из атрибутивного состава конфигурационных единиц и использовать их в скриптах сборщиков данных.
Явный пример использования данного сервиса - получение списка IP/DNS адресов конфигурационных единиц и опрос их, например по ICMP протоколу (ping).
⚠️ Если лицензия системы не позволяет работать с блоком настроек "Сбор данных по CMDB", данный блок настроек будет деактивирован.
Для включения сервиса необходимо активировать соответствующий переключатель в блоке настрое параметров сборщика.
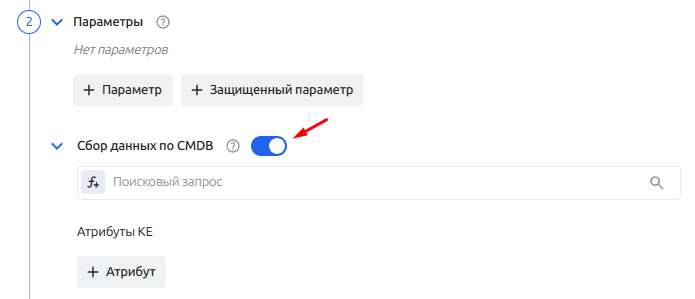
Настройка сбора данных по CMDB начинается с определения "фильтра КЕ" при помощи конструктора:
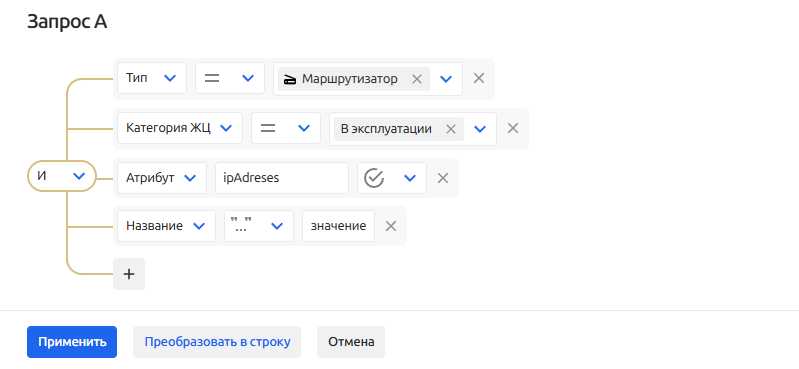
При запуске сборщика сервис выполняет фильтрацию КЕ согласно условиям заданным пользователем в настройках.
После формирования списка КЕ сервис записывает в кэш значения для указанных атрибутов. Помимо обновления кэша новыми КЕ подпадающими под заданную фильтрацию в настройках, сервис также обновляет актуальные данные для КЕ, отслеживая следующие события:
- Добавление нового сборщика с использованием сервиса CMDB
- Изменение фильтра КЕ в сервисе сборщика
- Изменение набора атрибутов КЕ в сервисе
- Изменение значений атрибутов КЕ
- Удаление сборщика
Доступны следующие условия фильтрации КЕ
- КЕ
- Ручной выбор КЕ из списка доступных в текущей рабочей группе, доступные операторы:
- Равно одному из
- Не равно одному из
- Ручной выбор КЕ из списка доступных в текущей рабочей группе, доступные операторы:
- Название
- По точному совпадению, доступные операторы:
- Равно
- Не равно
- По частичному совпадению, доступные операторы:
- Содержит
- Не содержит
- По точному совпадению, доступные операторы:
- Тип
- Ручной выбор типов КЕ из списка, доступные операторы:
- Равно одному из
- Не равно одному из
- Ручной выбор типов КЕ из списка, доступные операторы:
- Статус
- Ручной выбор статусов КЕ из списка, доступные операторы:
- Равно одному из
- Не равно одному из
- Ручной выбор статусов КЕ из списка, доступные операторы:
- Категория ЖЦ
- Ручной выбор категорий ЖЦ КЕ из списка, доступные операторы:
- Равно одному из
- Не равно одному из
- Ручной выбор категорий ЖЦ КЕ из списка, доступные операторы:
- Дата создания
- Задание абсолютных и относительных значений времени, доступные операторы:
- В интервале
- После
- До
- Задание абсолютных и относительных значений времени, доступные операторы:
- Дата изменения
- Задание абсолютных и относительных значений времени, доступные операторы:
- В интервале
- После
- До
- Задание абсолютных и относительных значений времени, доступные операторы:
- Метка или атрибут
- Задание названия метки или атрибута и применение следующих операторов к ним:
- Существует
- Отсутствует
- Равно
- Не равно
- Меньше
- Меньше или равно
- Больше
- Больше или равно
- Содержит (для массивов значений)
- Не содержит (для массивов значений)
- Содержит (для строк)
- Не содержит (для строк)
- Задание названия метки или атрибута и применение следующих операторов к ним:
Фильтр отберет КЕ, с которыми будет работать сборщик данных. Далее необходимо настроить маппинг атрибутов КЕ в параметры скрипта.
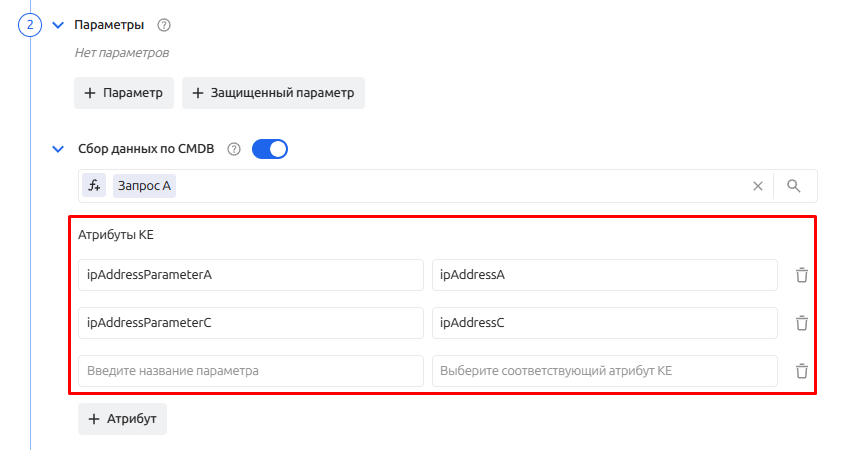
В поле слева необходимо определить название параметра, а справа название атрибута КЕ. В скрипте будет использоваться название параметра, доступ к которому осуществляется через шаблонизатор (Liquid или JSONPath).
Например, для скриншота выше, к атрибуту КЕ ipAddressA можно обратиться по следующим ключам: {{ vars.configItem.attrs.ipAddressParameterA }} или $.vars.configItem.attrs.ipAddressParameterA соответственно.
Для привязки будущих порогов к конфигурационным единицам, в скрипте можно использовать параметр $.vars.configItem.id, который содержит идентификатор КЕ, с атрибутами которой выполняется задание. Его можно добавлять вручную в виде дополнительных меток, если это позволяет сделать используемый плагин.
При использовании данного сервиса создается пул экземпляров заданий сборщика данных. Эти задания пропорционально распределяются на сервис безагентского мониторинга или на свободные агенты Monq, в зависимости от конфигурации выполнения. Если КЕ по условиям фильтрации много - возможно потребуется увеличение количества агентов или реплик сервиса безагентского мониторинга.
Если сбор данных по CMDB включен выполняется проверка на использование переменных атрибутов КЕ в скрипте сборщика. Если скрипт не содержит таких переменных пользователю отобразиться ошибка валидации YAML-скрипта: "YAML - задание не использует данные с КЕ, отключите сбор данных по CMDB".
Пример написания скрипта с использованием сервиса CMDB
Ниже приведен пример безагентского сбора метрик ЦПУ с хоста под управлением ОС Linux через SSH:
name: Безагентский сбор метрик с хостов под управлением ОС Linux
jobs:
- name: Получение метрик
steps:
- plugin: nodeInfoRemote
with:
scrapeTimeout: 30s
sshConfig:
host: $.vars.configItem.attrs.ipAddressParameterA
username: $.vars.username
password: $.vars.password
labels:
agentName: $.agentName
hostname: $.hostname
ip: $.hostAddress
source: nodeInfoRemote
configItemId: $.vars.configItem.id
scrapeConfig:
scrapeCpu:
enable: true
outputs:
result: $._outputs.metrics
artifacts:
- data: $.outputs.result
send-to: monq
type: metrics
Запуск и остановка сборщиков данных
По умолчанию, после создания сборщика данных, он находится в остановленном состоянии. В этом состоянии не происходит запуск выполнения скрипта сборщика по расписанию. Но при этом возможен ручной запуск сборщика, например при тестировании интеграции.
Перед запуском сборщика данных его необходимо настроить.
Если при запуске сборщика сервис не нашел свободных агентов для выполнения задания сборщика данных, сам сборщик перейдет в статус ошибка с сообщением: "Agent has no available slots".
Результатом выполнения скрипта сборщика является артефакт, далее передаваемый в поток данных Monq.
Статус выполнения
Для идентификации проблемных сборщиков, пользователям доступна информация о статусе сборщика.
Статус сборщика может принимать следующие значения:
- Неизвестно (серый) - сборщик еще не запускался.
- Ок (зеленый) - сборщик выполнился без ошибок.
- Предупреждение (желтый) - сборщик выполнил часть экземпляров заданий с ошибками, а часть успешно.
- Ошибка (красный) - в ходе выполнения сборщиком единичного задания возникла ошибка или все экземпляры завершились с ошибкой.
Если сработает блокировка по лимиту на пространство, статус сборщика будет "Ошибка" и будет иметь соответствующий лог с ошибкой.
При наведении на иконку статуса отображается текстовое описание ошибки, в зависимости от текущего статуса:
- Ошибка - название агента и лог с ошибкой
- Предупреждение - текст: "Некоторые экземпляры завершились с ошибкой:", название агента и лог с ошибкой, для тех заданий, что завершились с ошибкой, для заданий со статусом "ОК" записи не отображаются
- Ок - не имеет сообщений
- Unknown - не имеет сообщений.
Создание копии сборщика
Для удобства настройки множества сборщиков данных, в которых незначительные отличия в работе или периодичности запуска доступна опция клонирования в контекстном меню - "Создать копию".
Экспорт сборщиков данных
Если возникает необходимость переноса настроек сборщика на другой стенд Monq, его можно экспортировать. Для экспорта сборщика данных необходимо в контекстном меню выбрать пункт - "Экспорт".
При экспорте параметров сборщика не сохраняются защищенные переменные.
Импорт сборщиков данных
Импортировать сборщик можно на этапе создания, воспользовавшись полем импорт.
Удаление сборщиков данных
- Перейдите в раздел Сбор (ETL) - Сборщики данных через основное меню
- Найдите необходимый сборщик
- Воспользуйтесь вспомогательным меню ︙ для удаления соответствующего сборщика данных
Удаление сборщика является необратимым действием. Будьте внимательны при удалении.
Синтаксис скриптов сборщиков
Скрипт сборщика (сценарий) - содержит YAML-конфигурацию с одним или несколькими заданиями jobs, которые определяют логику сбора данных.
Перечисленные в скрипте задания выполняются параллельно в среде агента Monq или сервисе безагентского мониторинга.
Поля скрипта сборщика
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| name | строка | - | - | Название сценария |
| env | произвольный словарь | - | + | Глобальные переменные окружения, доступные в любом месте сценария |
| settings | объект настроек | - | - | Настройки выполнения сценария |
| jobs | массив служебных работ | + | - | Служебные работы сценария, выполняющиеся параллельно |
Структура Yaml:
name:
env:
setting:
jobs:
Поля служебных работ - jobs
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| name | строка | - | - | Название служебной работы |
| env | произвольный словарь | - | + | Переменные окружения, доступные в любом месте служебной работы. Значения перетирают значения совпадающих ключей в словаре сценария |
| settings | объект настроек | - | - | Настройки выполнения служебной работы |
| steps | массив шагов | + | - | Шаги служебной работы сценария, выполняющиеся последовательно |
| store | произвольный словарь | - | + | Сохраняемые в глобальном кэше переменные, значения которых передаются в следующий запуск сценария. Значения перетирают значения совпадающих ключей в словарях шагов. Также значения совпадающих ключей перетираются значениями в словарях других служебных работ, выполненных позже. |
| artifacts | массив артефактов | - | - | Сформированные артефакты выполнения служебной работы |
Структура Yaml:
name:
env:
setting:
jobs:
- name:
env:
settings:
steps:
store:
artifacts:
Поля шага служебной работы - steps
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| name | строка | - | - | Название шага служебной работы |
| env | произвольный словарь | - | + | Переменные окружения, доступные в любом месте шага служебной работы. Значения перетирают значения совпадающих ключей в словарях сценария и служебной работы. |
| settings | объект настроек | - | - | Настройки выполнения шага служебной работы |
| run | строка | + | + | Консольная команда для исполнения на внешнем агенте |
| plugin | строка | + | + | Команда агентского плагина для исполнения на агенте |
| with | произвольный словарь | - | + | Переменные исполняемой команды |
| with-secured | произвольный словарь | - | + | Защищенные переменные исполняемой команды, значения которых скрываются в логах |
| outputs | произвольный словарь | - | + | Возвращаемые значения |
| store | произвольный словарь | - | + | Сохраняемые в глобальном кэше переменные, значения которых передаются в следующий запуск сценария |
Выполнять shell-команды с применением команды run возможно только на агентах Monq.
Структура Yaml:
name:
env:
setting:
jobs:
- name:
env:
settings:
steps:
- name:
env:
settings:
run:
plugin:
with:
with-secured:
outputs:
store:
store:
artifacts:
Поля настроек - settings
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| shell | строка | - | - | Оболочка ОС. Может быть указан либо путь к исполняемому файлу, либо одно из предзаданных значений |
Структура Yaml:
name:
env:
setting:
jobs:
- name:
env:
settings:
shell: bash
steps:
- name:
env:
settings:
shell: sh
run:
plugin:
with:
with-secured:
outputs:
store:
store:
artifacts:
Предустановленные значения shell
| Значение | Заменяющая команда |
|---|---|
| cmd | cmd.exe /C <command> |
| bash | bash -c "<command>" |
| powershell | powershell.exe -Command <command> |
| pwsh | pwsh -Command <command> |
| sh | sh -c '<command>' |
Для различных семейств ОС используются значения по умолчанию:
- Windows —
cmd- Unix —
bashВ остальных случаях нужно обязательно явно указать желаемую оболочку.
Поля артефакта - artifacts
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| name | строка | - | - | Название артефакта |
| type | строка | - | - | Тип артефакта. Допустимые значения: metrics (для отправки метрик), logs (для отправки событий и логов). |
| paths | массив строк | - | + | Пути к файлам, которые будут помещены в один архив |
| files | массив строк | - | + | Список путей к файлам, которые будут переданы отдельно |
| data | произвольный объект | - | + | Данные артефакта |
| send-to | объект настроек отправки артефакта | - | - | Настройки отправки данных артефакта |
Структура Yaml:
...
artifacts:
- name:
type:
paths:
files:
data:
send-to:
...
Данные артефакта
В поле data пользователи, при написании сценария могут сформировать модель события которое будет отправлено в коллектор Monq.
При отправке различных типов данных через артефакт, следует учитывать характер конкретного типа и способы использования шаблонизатора.
Например, если у нас имеется следующее событие, хранящееся в переменной outputs.test.responseData:
{
"string": "text",
"number": 123,
"arrayString": ["test1", "test2", "123"],
"arrayNumber": [1, 2, 3],
"boolean": false,
"null": null,
"object": {
"string": "text",
"number": 123,
"array": ["test1", "test2", "123"],
"boolean": false,
"null": null
}
}
-
string- чтобы отправить значение поля с типомstring, его нужно обязательно заключать в кавычки, иначе данные будут конвертированы в невалидныйjsonи соответственно не будут отправлены. Пример использования:artifacts:
- data: >
{
"string": " {{ outputs.test.responseData.string }} "
} -
arrayString,object,number,boolean- чтобы отправить значение поля с одним из перечисленных типов, нужно воспользоваться следующей конфигурацией (без использования кавычек):artifacts:
- data: >
{
"object": {{ outputs.test.responseData.object }}
} -
null- для обработки исключений с пустыми полями, можно воспользоваться следующей конфигурацией:artifacts:
- data: >
{
"null": {% if outputs.test.responseData.null == nil %} null {% endif %}
}
Поля настроек отправки артефакта
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| monq | объект отправки в Monq | - | - | Отправка в Monq |
| api | объект настроек API запроса | - | - | Настройки отправки через API запрос |
Поля настроек API запроса
| Название | Тип | Обязательно | Шаблон | Описание |
|---|---|---|---|---|
| method | строка | - | + | Метод запроса. По умолчанию POST |
| uri | строка | - | + | URI запроса |
| headers | произвольный словарь | - | + | Заголовки запроса |
| query-params | произвольный словарь | - | + | Параметры запроса |
| media-type | строка | - | + | Тип тела запроса. По умолчанию application/json. |
Минимальная структура сценария
Для каждого YAML сценария должна быть определена минимальная структура в одной из следующих вариаций:
jobs:
- steps:
- run: echo Hello!
jobs:
- steps:
- plugin: pluginName
jobs:
- steps:
- plugin: pluginName
run: echo Hello!
Если указаны и команда плагина
plugin, и консольная командаrun, то сначала выполнится плагин, а потом последовательно выполнится консольная команда.
Шаблонизация
В некоторых полях сценария поддерживается указание шаблонов. В шаблонах можно обращаться к различным группам переменных.
Доступно несколько шаблонизаторов:
-
jobs:
- steps:
- run: date /c
store:
currentDate: $._outputs.shell -
jobs:
- steps:
- run: date /c
store:
currentDate: {{ _outputs.shell }}
Группы переменных
В YAML-сценарии можно обращаться к переменным из разных групп. Они отличаются местом определения и областью видимости.
-
env- глобальный словарь переменных окружения, доступный в любом месте сценария. Значения могут быть заданы в любом месте сценария, служебной работы или шага. Значения передаются во вложенные элементы, при этом дочернийenvможет перезаписать одноименные ключи родителя.
Пример обращения:---
jobs:
- steps:
- run: rm -rf ${WORKSPACE}/allure-results/* && /opt/venv/bin/py.test -v /opt/tests/demo/docs.monq/test_docs.py --alluredir ${WORKSPACE}/allure-results
env:
X_FMonq_PROJECT_KEY: 97911b15-d756-4376-802d-4ae54ab29354
X_SMON_STREAM_KEY: 5ba11e94-2152-4428-b9fb-56988090cd71
Monq_URL: https://monq.example.ru
WORKSPACE: /opt/workspace -
vars- переменные агентского задания, которые пользователь определяет в параметрах сборщика, а также системные переменные.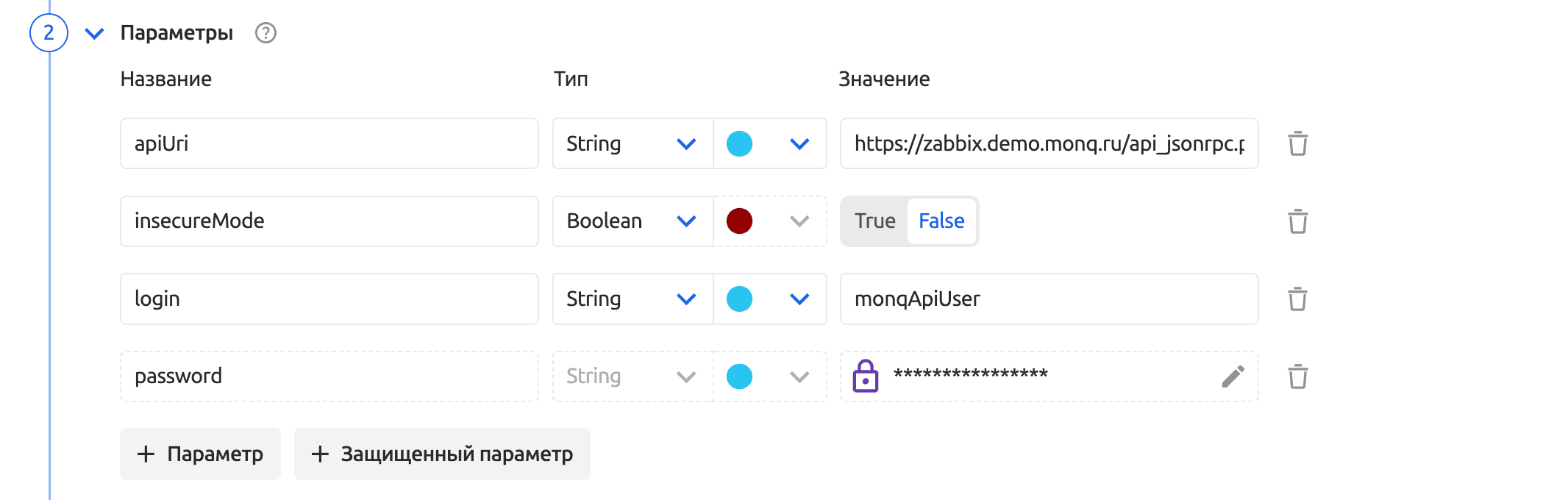
Примеры обращения:
$.vars.apiUri- если обращение прямое, или{{ vars.password }}- если значение спрятано в кавычках---
jobs:
- name: Get hosts
steps:
- name: Auth in Zabbix
plugin: httpPlugin
with:
url: $.vars.apiUri
#...
insecure: $.vars.insecureMode
body: >
{
...
"params": {
"username": "{{ vars.login }}",
"password": "{{ vars.password }}"
},
...
}В неявном виде может передаваться информация о потоке данных через объект
stream, например:$.vars.stream.keyили$.vars.stream.id -
storage- глобальный кэш сценария. Значения попадают сюда через произвольные словариstoreи доступны:- на последующих шагах текущего запуска
steps - в последующих служебных работах
jobs - в следующих запусках сценария
Пример обращения:
$.storage.token - на последующих шагах текущего запуска
-
outputs- общий словарь возвращаемых значений служебной работыjob.
Его содержимое формируется в блокеoutputsотдельных шаговsteps.
После завершения шага переменные становятся доступны всем последующим шагам этой же служебной работы и ее артефактам. -
_outputs- «черновик» результатов текущего шагаstep.
Сюда попадает все, что возвращает плагин или командаrunв процессе выполнения шага.
По умолчанию в_outputsдоступно полеshell— stdout успешно выполненной консольной команды.Принцип работы
outputsи_outputs:- Выполняется шаг
step— плагин или командаrunзаполняет_outputs
например, ключамиshell,statusили иными данными плагина - В этом же шаге вы решаете, что сохранить: указываете блок
outputs, где указываете ключи и записываете в них нужные значения из_outputs
Если ничего не перенести, данные останутся локальными и исчезнут после шага - Следующие шаги и артефакты обращаются уже к общему
outputs, то есть к тем значениям, которые вы сохранили на предыдущих шагах.
Примеры обращений:
---
jobs:
- name: Get hosts
steps:
- name: STEP 1 - Auth in Zabbix
plugin: httpPlugin
#...
outputs: # - ОБЩИЙ СЛОВАРЬ, СЮДА БУДУТ ЗАПИСАНЫ ЗНАЧЕНИЯ, ОПИСАННЫЕ НИЖЕ
token: $._outputs.responseData.result # - ОБРАЩЕНИЕ К ВРЕМЕННОМУ СЛОВАРЮ _outputs ДЛЯ ЗАПИСИ ЗНАЧЕНИЯ В token
- name: STEP 2 - Get hosts
#...
body: >
{
...
"auth": "{{ outputs.token }}", # - ИЗВЛЕЧЕНИЕ ИЗ ОБЩЕГО СЛОВАРЯ outputs ЗНАЧЕНИЯ token, ПОМЕЩЕННОГО ТУДА НА ПРЕДЫДУЩЕМ ШАГЕ
...
outputs: # - ПОМЕЩЕНИЕ В ОБЩИЙ СЛОВАРЬ НОВОГО ЗНАЧЕНИЯ - result
result: $._outputs.responseData # - result ЗАПОЛНЯЕТСЯ ЗНАЧЕНИЕМ responseData ИЗ ВРЕМЕННОГО СЛОВАРЯ _outputs ТЕКУЩЕГО ШАГА---
jobs:
- steps:
- run: curl -s https://example/api
outputs: # - ОБЩИЙ СЛОВАРЬ
shell_response: $._outputs.shell # - ИЗ ВРЕМЕННОГО СЛОВАРЯ _outputs БЕРЕМ СЫРОЕ ЗНАЧЕНИЕ И ПОМЕЩАЕМ В КЛЮЧ shell_response
artifacts:
- data: '{{ outputs.shell_response }}' # - ИЗВЛЕКАЕМ ИЗ ОБЩЕГО СЛОВАРЯ outputs ЗНАЧЕНИЕ shell_response
send-to:
#... - Выполняется шаг
Системные переменные
userspaceId— идентификатор пользовательского пространства.baseUri— URL адрес текущего пространства Monq (например,https://monq.example.com/).agentName— имя агента, null для динамических агентов.hostname— DNS имя хоста.hostAddress— IP адрес хоста.
Примеры скриптов с использованием команды run
Ниже приведены примеры скриптов, которые можно использовать в сборщиках данных.
Пример работы с API
Пример сценария Задания агента для выполнения запроса к "fake API" jsonplaceholder.typicode.com.
---
jobs:
- steps:
- run: curl -s https://jsonplaceholder.typicode.com/todos/11
outputs:
out_json: $._outputs.shell
artifacts:
- data: '{{ outputs.out_json }}'
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
В данном сценарии представлен один шаг выполнения - run.
При помощи run на внешнем агенте выполняется запуск утилиты curl с соответствующими параметрами.
Результат выполнения команды STDOUT сохраняется как артефакт в переменную out_json из специальной группы переменных _outputs.
Записанные данные артефакта в переменной outputs.out_json, при помощи инструкции send-to, передаются в текущий поток данных, где:
uri- URL публичного API потока данных.$.vars.stream.key- API-ключ текущего потока данных.
После успешного выполнения задания в Событиях появится следующая запись:
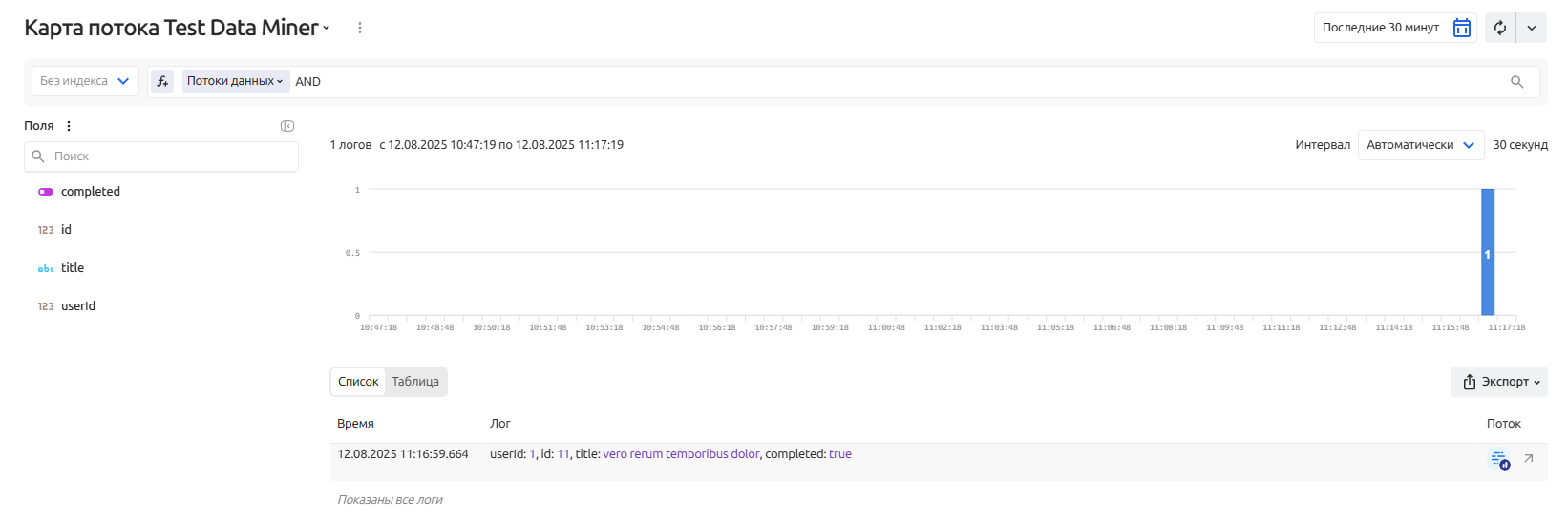
Пример сбора информации с системы в формате json
Приведенный пример задания выполняет на Агенте команду kubectl get ingresses -n kube-system kubernetes-dashboard -o json и передает результат выполнения в JSON объекте source.value в Monq.
---
jobs:
- steps:
- run: kubectl get ingresses -n kube-system kubernetes-dashboard -o json
outputs:
data: $._outputs.shell
artifacts:
- data: |
{
"value": {{ outputs.data }}
}
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
Пример сбора информации с системы в формате text/plain
Приведенный пример задания выполняет на Агенте команду ls -la / и передает результат выполнения в Monq.
jobs:
- steps:
- run: ls -ltr /opt/monq-agent/
outputs:
result: $._outputs.shell
artifacts:
- data: "{{ outputs.result }}"
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: text/plain
Обратите внимание, на выбранный тип media-type: text/plain и настройте соответствующим образом обработчик в потоке данных.
Например можно выбрать обработчик Automaton и весь полученный текст будет записан в поле source.sourceText первичного события:
{
"source.sourceText": "total 108328\n-rwxr-xr-x 1 root root 110912564 Jul 7 17:27 monq-agent\n-rw-r--r-- 1 root root 467 Aug 12 11:12 monitoring-agent.conf\ndrwxr-xr-x 2 root root 4096 Aug 12 11:28 plugins",
"_stream.name": "Test Data Miner"
}
Пример запуска функциональных тестов pytest
Приведенный пример запускает Python Framework pytest для проведения функционального тестирования и отправки результатов модуль Автотестов.
В данном примере отправка файла
allure-result.zipв API - Автотесты выполняется средствами Python
---
jobs:
- steps:
- run: rm -rf ${WORKSPACE}/allure-results/* && /opt/venv/bin/py.test -v /opt/tests/demo/docs.monq/test_docs.py --alluredir ${WORKSPACE}/allure-results
env:
X_FMonq_PROJECT_KEY: 97911b15-d756-4376-802d-4ae54ab29354
X_SMON_STREAM_KEY: 5ba11e94-2152-4428-b9fb-56988090cd71
Monq_URL: https://monq.example.com
WORKSPACE: /opt/workspace
outputs:
data: $._outputs.shell
artifacts:
- data: '{ "value": "{{ outputs.data }}" }'
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
Пример получения проблем из Dynatrace
Данный сценарий запрашивает проблемы из API Dynatrace и отправляет в Monq.
---
jobs:
- steps:
- run: 'curl -s https://{dynatrace-url}/api/v2/problems --header \"Authorization: Api-Token {token}\"'
outputs:
out_json: "$._outputs.shell"
artifacts:
- data: "{{ outputs.out_json }}"
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
В событиях и логах результат представлен в виде структурированного JSON объекта.
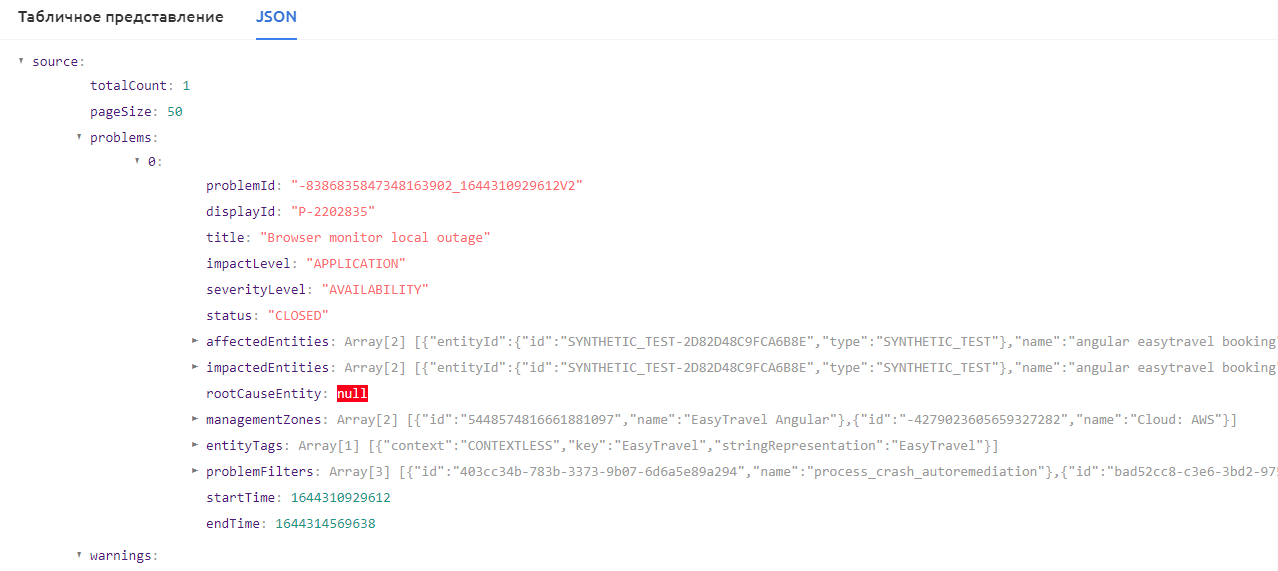
Пример выполнения запроса к базе данных PostgreSQL
---
jobs:
- steps:
- run: 'PGPASSWORD=password psql -h localhost -U zabbix -d zabbix -c \"select json_agg(users) from users;\" -qtAX'
outputs:
out_json: "$._outputs.shell"
artifacts:
- data: "{{ outputs.out_json }}"
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
Пример выполнения запроса к базе данных MySQL
---
jobs:
- steps:
- run: 'mysql -uroot -ppassword mysql -e \"select JSON_ARRAYAGG(JSON_OBJECT(\"name\", User, \"passwd\", Password)) from user;\" -s -N'
outputs:
out_json: "$._outputs.shell"
artifacts:
- data: "{{ outputs.out_json }}"
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json
Пример выполнения запроса информации о подах кластера Kubernetes
---
jobs:
- steps:
- run: kubectl get pod -n sock-shop -o json
outputs:
data: $._outputs.shell
artifacts:
- data: "{{ outputs.data }}"
send-to:
api:
uri: "{{ baseUri }}api/public/cl/v1/stream-data"
headers:
x-smon-stream-key: $.vars.stream.key
media-type: application/json