Тракт обработки данных в Monq
С основным трактом обработки данных в Monq можно ознакомится на схеме:
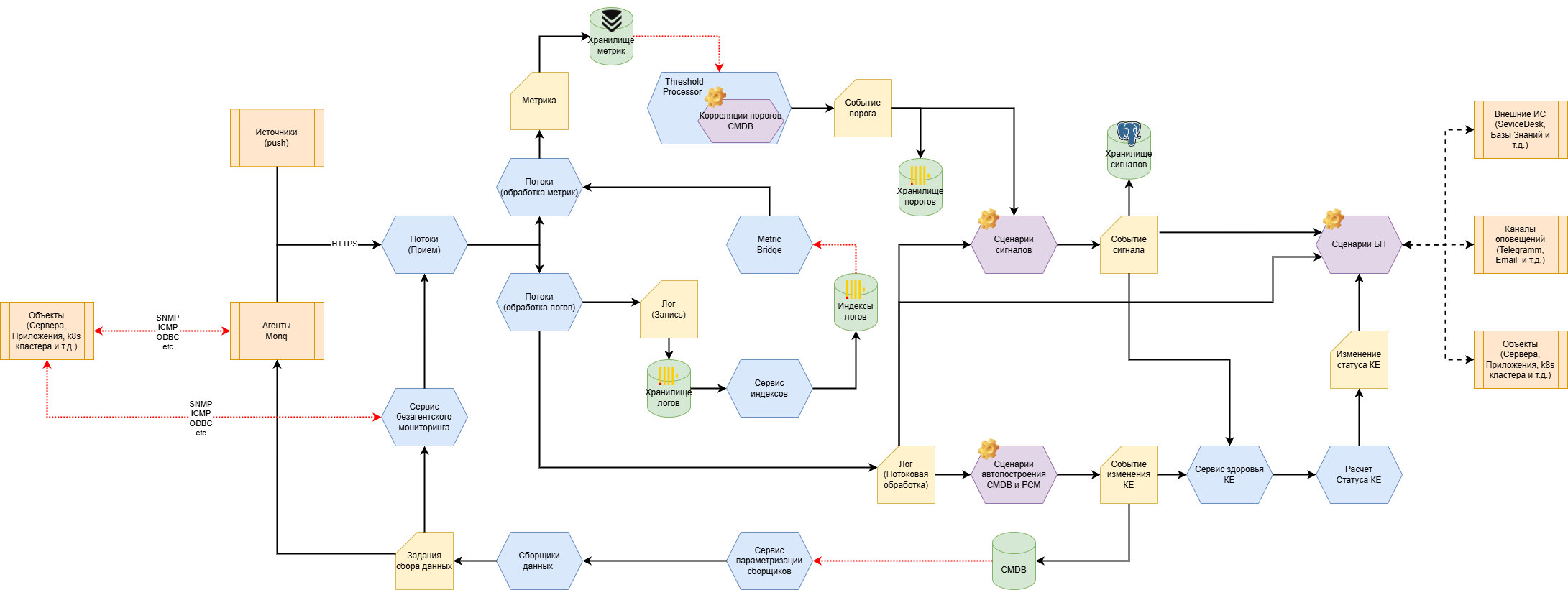
Тракт обработки состоит из следующих основных блоков:
- Сбор данных:
- Прямой прием push-сообщений из внешних систем.
- Активный сбор данных агентами Monq или сервисом безагентского мониторинга, где Monq выступает инициатором получения данных (SNMP-запросы, ICMP-проверки, HTTP-probe). Реализуется через настройку сборщиков данных.
- Пассивный сбор данных агентами Monq: постоянное прослушивание и захват данных (SNMP-trap, TCP-порты, log tailing). Реализуется через рабочие конфигурации агентов.
- Первичная обработка данных (ETL) - классификация, нормализация и разметка данных. В зависимости от типа данных они направляются в соответствующий тип потока данных:
- Схема прохождения событий и логов.
- Схема прохождения метрик.
- Дополнительные возможности:
- Индексы (позволяет настроить создание пользовательских индексов логов - специализированных структур для оптимизированного хранения и анализа данных).
- MetricBridge (позволяет настроить преобразование логов во временные ряды с последующим сохранением в хранилище временных рядов).
- Преобразование данных мониторинга в пороги и сигналы:
- Для генерации из временных рядов событий используется процессор порогов (Threshold Processor). Данный сервис по расписанию запускает правила расчета порогов. Cобытие порога, сформированное процессором порогов, поступает на узел постобработки, где порог может быть дополнительно обогащен, в частности скоррелирован с существующими КЕ (сценарии обогащения реализованы при помощи встроенного low-code движка). Далее обогащенный порог поступает на расчет сигналов.
- Сигнал предназначен для корреляции первичных событий, сформированных из логов, и порогов, сформированных из временных рядов. Для создания/изменения сигналов, а также их привязки к КЕ используются сценарии формирования сигналов (правила), создаваемые при помощи встроенного low-code движка, позволяющего запрограммировать любую логику.
- Автообнаружение и построение CMDB и РСМ - происходит на основе собираемых логов. Источниками таких логов могут быть как первичные объекты, так и уже существующие CMDB-системы клиента, другие системы мониторинга, реестры и пр. Обработка таких событий также реализована при помощи встроенного low-code движка: по результатам работы сценариев в CMDB Monq появляются/изменяются КЕ с заданными наборами атрибутов, которые можно конфигурировать.
- Постобработка:
- Расчет здоровья и статусов КЕ:
- Сигналы вызывают пересчет здоровья - интегрального показателя состояния объектов мониторинга (КЕ). Сигналы оказывают влияние не только на связанные с сигналами КЕ, но и согласно ресурсно-сервисной модели распространяется влияние по всему графу.
- Пороговые значения здоровья изменяют статус КЕ.
- Автоматизация бизнес-процессов:
- Различные события в системе (а также расписание) используются для запуска пользовательских бизнес-процессов (набора сценариев): оповещений, регистрации инцидентов, вызова API внешних систем, запуска скриптов и т.д..
- Бизнес-процессы автоматизации пишутся при помощи встроенного no-code движка.
- Расчет здоровья и статусов КЕ:
Схема прохождения событий и логов
Схема описывает процесс получения, обработки и сохранения событий и логов из внешних источников.
Данная архитектура предполагает возможность получать текстовые данные в любом формате, с последующим парсингом и записью полученных событий в БД (если необходимо).
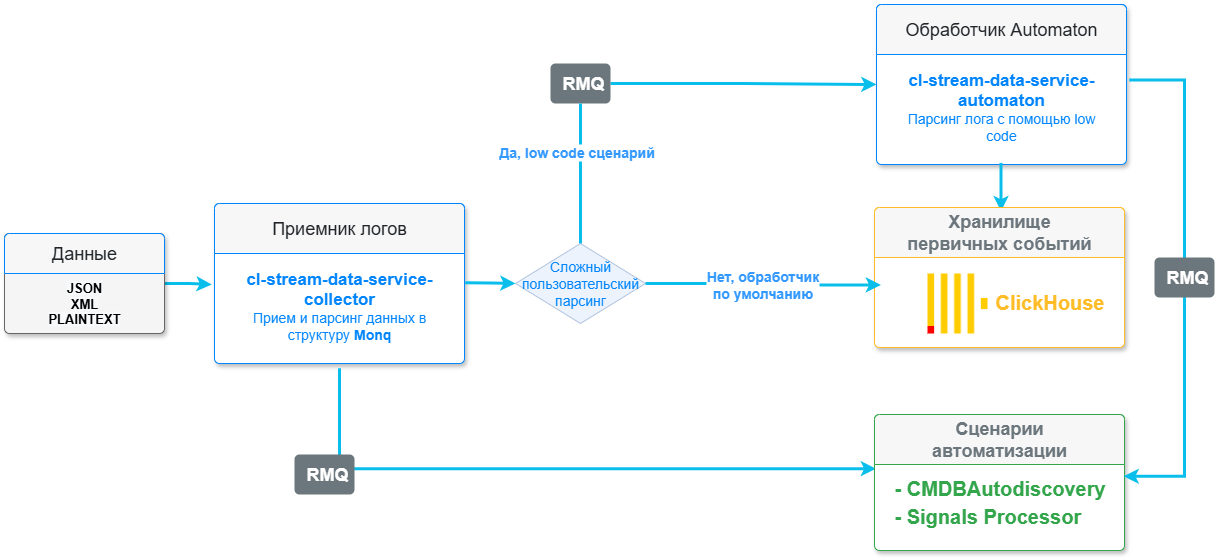
Процесс обработки событий предполагает наличие следующих звеньев:
-
Приемник логов – точка прослушивания HTTP запросов. Сервис проводит валидацию API-ключа потока данных и входной модели в зависимости от типа входных данных. Сообщение проходит процесс парсинга встроенным парсером (Nginx, Docker, Syslog и др.) или отправляются на парсер low-code движка Automaton. Далее согласно пользовательским настройкам определенного потока данных:
- либо принятые данные сохраняются в хранилище логов, реализованное на основе СУБД Clickhouse;
- либо поступают на дальнейшую постобработку (как с сохранением полученных логов в хранилище, так и без оного) средствами встроенного low-code движка, позволяющего запрограммировать любую логику работы с сигналами и CMDB Monq.
-
Обработчик Automaton - опциональное звено, в котором доступна реализация сложной пользовательской логики такой как:
- парсинг и превращение текста в JSON;
- обработка пакетных событий, например, извлечение из этих событий единичных элементов;
- преобразование входной модели, например, добавление вычисляемого поля или замена типа поля в модели;
- добавление системных меток для событий.
Схема прохождения метрик
Схема описывает процесс получения, сохранения и обработки показателей мониторинга в виде метрик из внешних источников.
Данная архитектура предполагает возможность получать метрические данные из внешних систем мониторинга, таких как Zabbix и Prometheus. А также собирать метрики с конечных устройств и сервисов при помощи плагинов к агенту Monq.
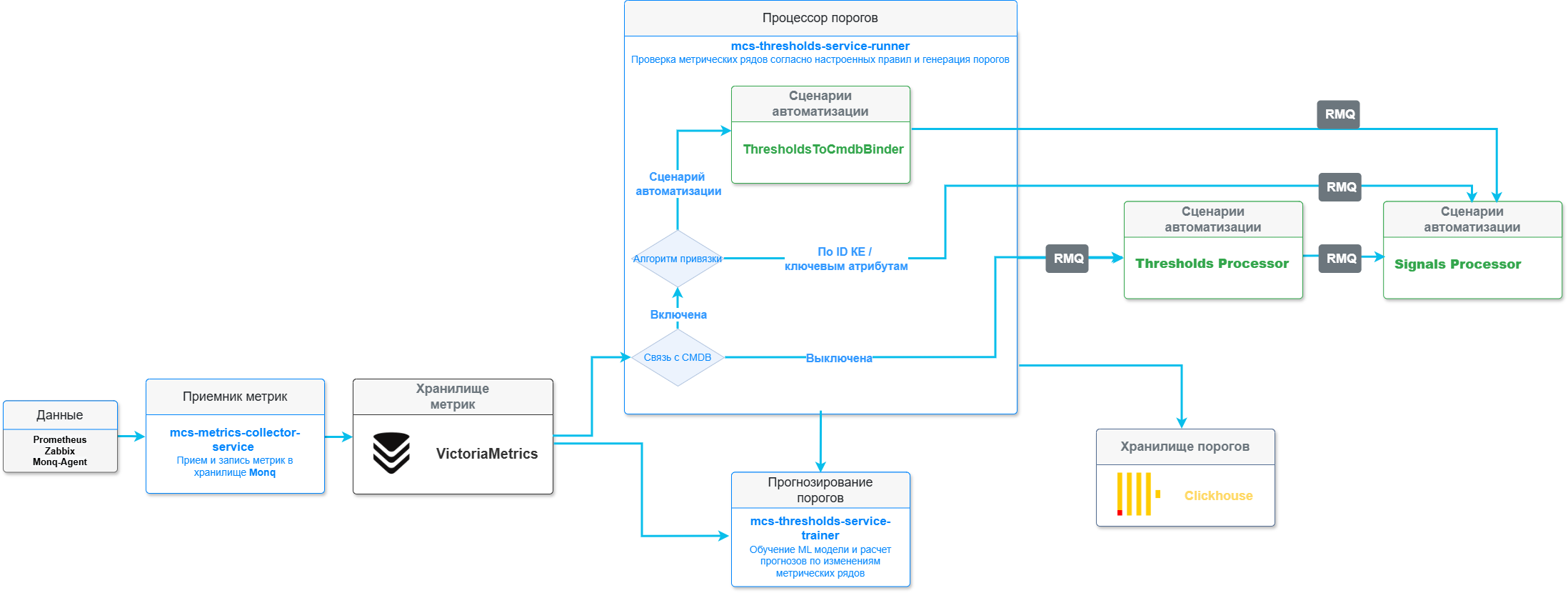
Процесс обработки метрик предполагает наличие 2-х звеньев:
-
Приемник метрик – точка прослушивания HTTP. Сервис в соответствии с указанным в потоке типом обработчика принимает и обогащает дополнительными метками метрики по встроенным алгоритмам и записывает их в хранилище, реализованное на основе СУБД VictoriaMetrics.
-
Процессор порогов - данный сервис выполняет проверку записанных в хранилище метрических рядов по преднастроенным в интерфейсе Monq Правилам порогов. В результате работы генерирует активные пороги, которые проходят дальнейшую обработку как обычные события. Опционально выполняется привязка сгенерированных порогов к КЕ по выбранному в правиле алгоритму привязки.